How does Google find and index Web pages

It is the digital age and we live in a convenient world where we can get the answers to most questions by just googling them. It takes less than a minute to enter a search query, and then, just at the click of a button, you get the answers you were looking for. The most relevant, appropriate, and high quality content chosen from millions of sources is neatly arranged just for you! How does Google do this? How does it manage to scour through trillions of pages in just a couple of seconds and give you the accurate response, every single time?
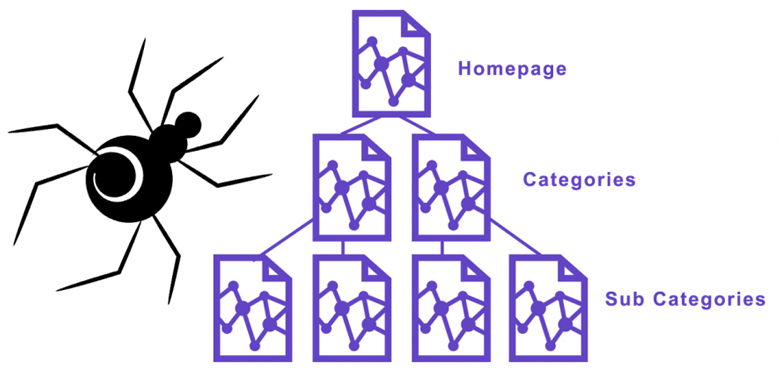
This is made possible by the techniques of crawling and indexing. The sheer amount of data available on the internet is humongous. With lakhs of pages being added, updated, and modified daily, it becomes a tedious task to make note of every new addition. To tackle this, Google uses crawlers or spiders, which true to their name, crawl the World Wide Web i.e. the internet, to make note of all the new pages being added on the internet. Once the pages are traversed, certain information is stored in Google’s vast database, an index of all the pages is created, and then the relevant pages are returned back as answers to user queries. Let’s now look at this entire process in detail.
What Is Crawling in SEO?
Crawling is the process by which the Web crawlers, or Googlebot visits the different web pages in order to track them. Once the Googlebot visits a certain website URL, it will scour the entire page, and make a copy of it to be added into the database. Googlebot will make note of all the data and content on the page, including the images, audio, and video files on the web page. It will also crawl all the pages linked with a given webpage, and keep adding them to the repository. It is thereby recommended that all the pages in your website must be well linked with each other.
Additional Read: What Is Crawl Budget in SEO And How It Will Affect Your Website Ranking.
How Google’s Site Crawlers Index Your WebPages?
Crawlers always make use of XML Sitemaps, which are basically an outline consisting of all the links of a given web page. This is why it becomes imperative to submit an XML sitemap for your website to ensure that Googlebot doesn’t skip any vital pages. However to avoid unnecessary and redundant pages from being crawled, you can add a robot.txt file to them. This will ensure that crawlers skip those pages. It is also advisable that the metadata or metatags of your page aptly describe the page. This helps the Googlebot to catalogue the page into relevant categories.
Anyone familiar with SEO would know that the higher the number of legitimate backlinks a page has, the higher are its chances of being ranked. The same applies for internal linking. If a website has all its pages linked together concisely, it makes it a lot easier for web crawlers to access them.
Once a web page and its related links have been crawled and saved, the next step is Indexing.
What is Google Indexing?
Indexing refers to the process of cataloguing information and content from the crawled web pages and sorting them into different categories. Basically, Google creates and maintains an index of all the web pages it crawls and saves them into a structured database. Then when a particular search query pops up, the algorithm picks out the relevant web pages from the repository and presents it to the user.
Google uses a complex algorithm that constantly keeps defining parameters to parse and categorise content, and sorts the crawled data into indexed registries, from where it is easier to retrieve using data mining techniques.

Of the lakhs of pages present on any given topic, how then is it possible to get your web page to rank higher? Google’s algorithm has a few key features that can solidify your ranking in the Google database. Web pages with relevant titles in the URL, succinct metatags, appropriate page descriptions, well-connected internal links, and high-ranking backlinks, score higher than their counterparts. As such, they get a higher ranking and show up as the topmost results on the SERP (Search Engine Result Page).
As more and more web pages keep getting added and updated on the internet, Google constantly has to keep crawling and indexing web pages, which in turn, keeps changing the ranking of the web pages. This is why Search Engine Optimisation is a continuous process.
A good practice would be to connect all pages with each other creating a Web of pages and submitting the sitemap to Google via Webmaster Tools, every time a new page is added or some content is modified. If you provide quality content, ensure that your web pages are quick to load, have faster response times, and have web pages that are compatible with smartphones, it will automatically increase the frequency with which Googlebot tracks your page.
Additional Read: Why a Responsive Website is No Longer “Optional” in 2019
Thus, once a website features prominently in Google’s ranking system, it automatically gets indexed frequently and effectively. This just reinstates the fact that if you maintain a quick-loading, efficient website with consistently good content, Google will do the rest!

![]()